How batch size affects token cost and speed
where is batch size, is active parameters, and FLOPs is the compute throughput of the hardware.
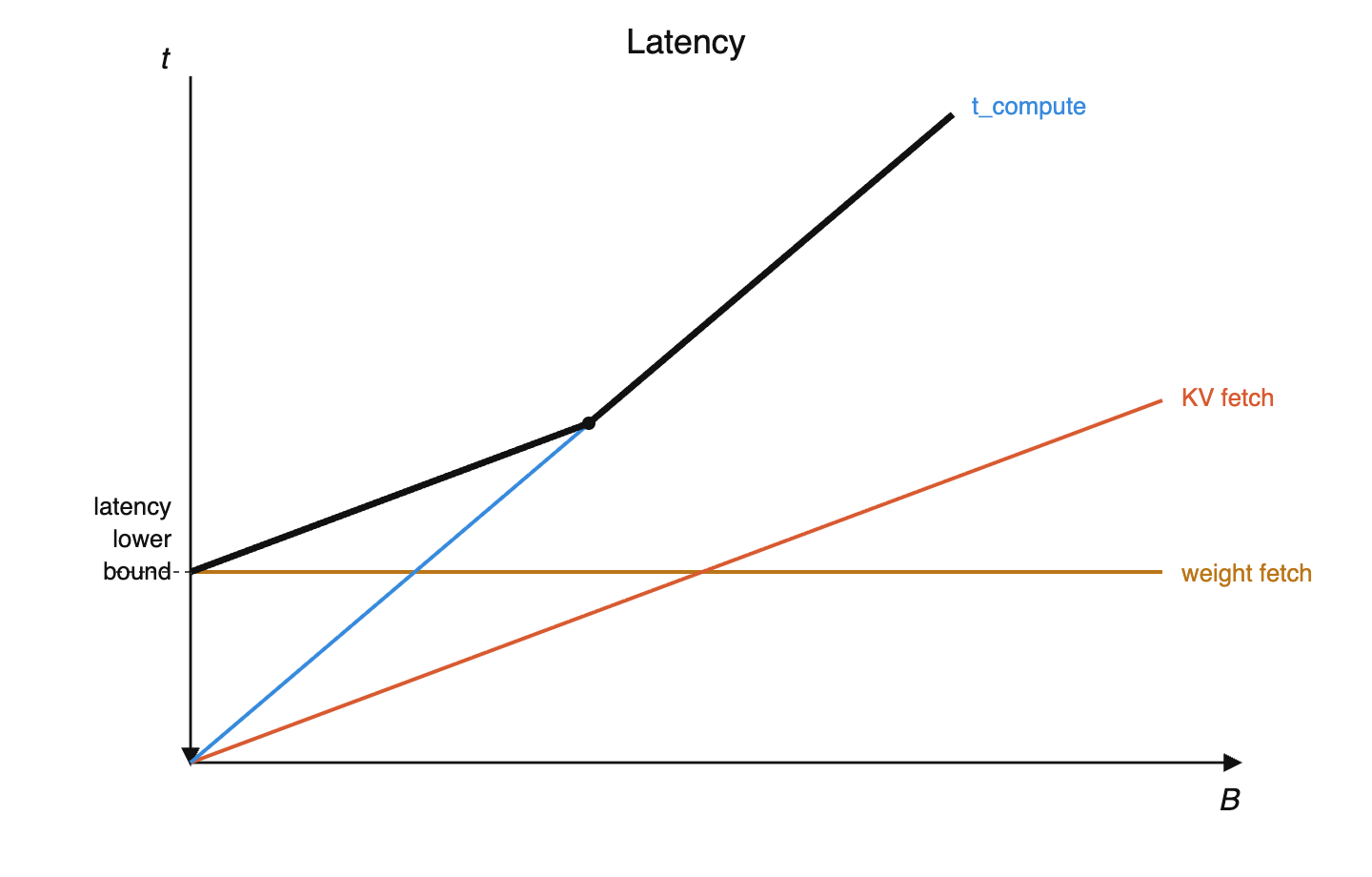
Because you still have to load all the active parameters into memory.
Compute time, and memory time for KV cache fetches, cannot be amortized with batch size.
FLOPs / byte.
Set compute time = memory time (at equality, both resources are fully saturated):
Solve for :
So .
Why: compute scales with (each token needs its own matmul), but weight fetches don't (load once, reuse across batch). Need enough tokens to amortize the fetch.
DeepSeek V3: active → .
20ms is the HBM drain time — memory capacity ÷ memory bandwidth. E.g. Rubin: .
Faster than 20ms is impossible because you physically can't read all the weights from HBM in less time than bandwidth allows.
Slower than 20ms means you're just leaving the FLOPs idle, because there's nothing left to read.
How MoE models are laid out across GPU racks
MoE communication is all-to-all (any GPU's tokens may route to any other GPU's experts).
Within a rack, NVLink connects every GPU to every other at full bandwidth, which is a perfect fit for all-to-all. Across racks, scale-out is slower and bottlenecks the all-to-all.
How pipeline parallelism moves model layers across racks
At the beginning of the batch, the GPUs dedicated to the final layers are not being used, and conversely at the end of the batch, the GPUs dedicated to the first layers are not being used.
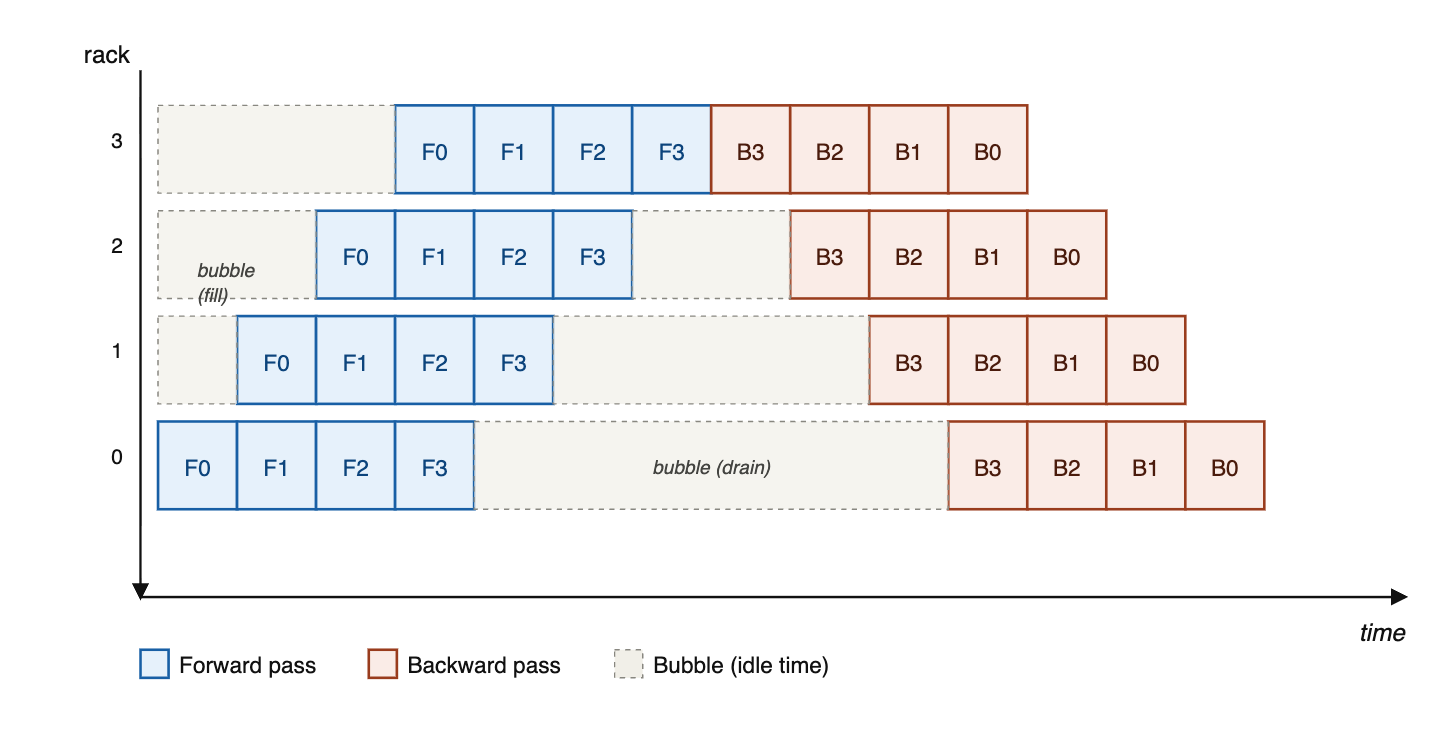
You need to consolidate gradients and update the model before you process the next batch.
Keeping stages busy requires micro-batches in flight, so concurrent sequences scale with .
Given that KV cache often dominates memory at long context lengths, pipelining's value is limited.
Why Ilya said, "As we now know, pipelining is not wise."
You're adding architecture constraints — things like Kimi's attention-to-residuals (where each block attends to all previous layers' residuals) become very difficult when those residuals live on different pipeline stages. Similarly, interleaving sliding-window and global attention layers could cause load imbalance across stages. Dealing with all this slows down research iteration, which is the greatest sin you can commit.
Because of RL, models may be 100× over-trained beyond Chinchilla-optimal
2 FLOPs per parameter per token for the forward pass (multiply + add). Backward pass is forward because you compute gradients w.r.t. both input matrices. So .
(the formula — forward + backward)
(2 if you don't train on the rollout and do forward only, up to 6 if you do; inefficiency from low MFU during decode)
(forward pass only; lower MFU during decode)
If pre-training, RL, and inference costs trade off (more pre-training → less RL/inference needed for same quality, and vice versa), the optimum is approximately where all three are equal.
Deducing inference memory costs from API pricing
Below this point, you're compute bound, whose cost is flat as context length increases.
Above this point, you're memory time bound, thanks to KV cache growing, and that increases linearly with context length.
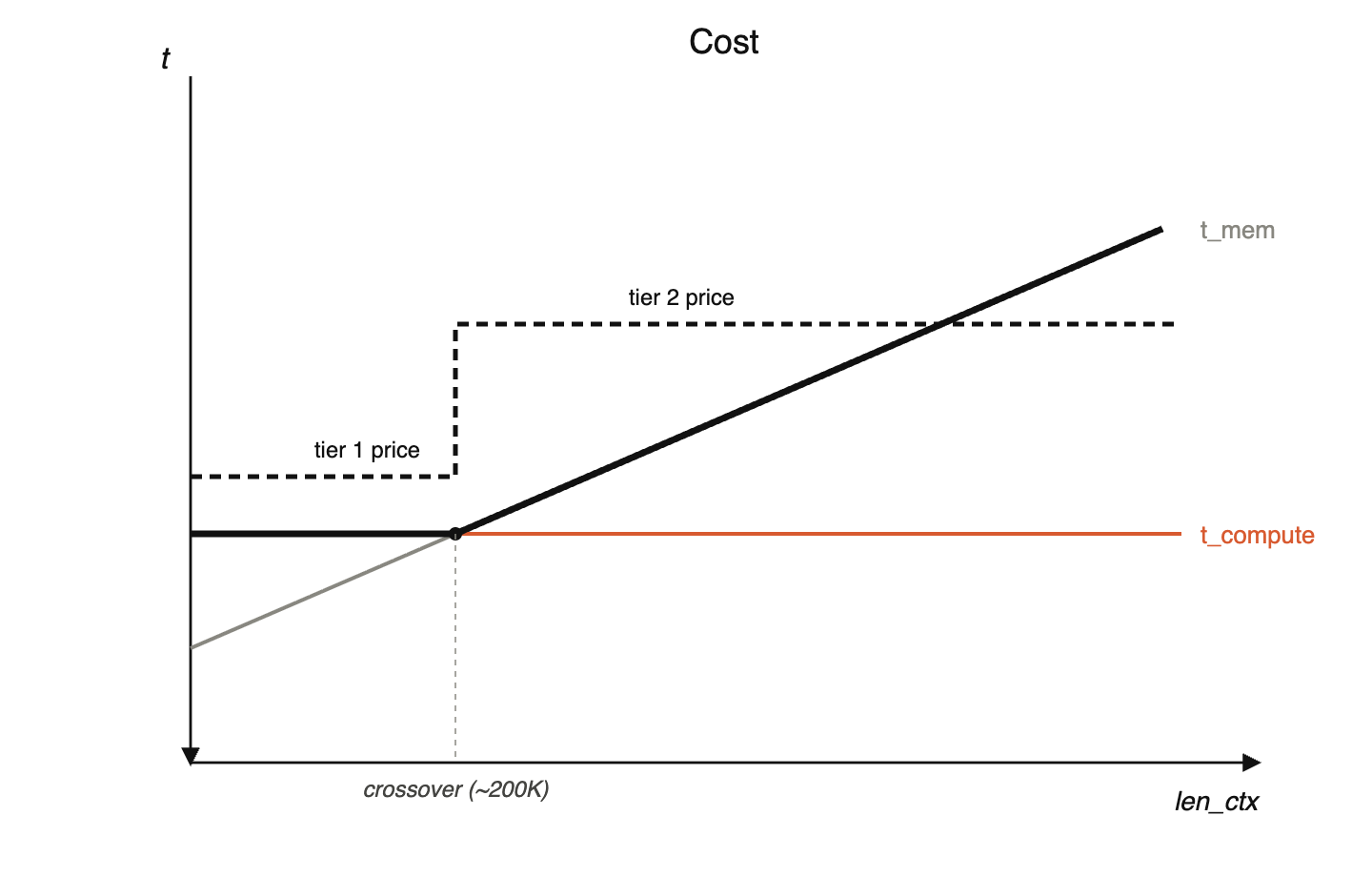
At the crossover, :
Solve for bytes/token:
Plug in: , → .
MFU during decode is about that during prefill.
This is because in prefill, you're processing the whole sequence in parallel, so the weight fetch can be amortized across lots of compute, whereas in decode, you have to load all the weights in just to process one more token, which means you're wasting FLOPs while you're waiting for the weights to show up from memory.
Loading KVs from memory is much cheaper than recomputing.
Convergent evolution between neural nets and cryptography
They've both had this convergent evolution where cryptographic protocols need every output bit to depend on every input bit in complicated ways, and similarly, NNs need output to make connections between inputs.
Cryptographic protocols take something which has a lot of structure and make it seem indistinguishable from random. Whereas NNs take something which may look random and extract structure from it.